umpy와 pandas를 불러온 뒤,
간략한 테스트용 데이터프레임을 생성합니다.
import numpy as np
import pandas as pd
df = pd.DataFrame([[4, 9], [1, 4], [5, 6]], columns=['A', 'B'])
데이터프레임 생성
데이터프레임 생성이 궁금하다면 아래의 링크를 참고해보세요.
파이썬 판다스 데이터프레임 생성 - 비전공자도 이해하는 설명, python pandas DataFrame and pip list dict n
판다스 데이터프레임 쉽게 생성하기 비전공자 입장에서 판다스 데이터프레임을 생성하는 것조차 이해가 잘 되지 않아요. 저 같은 경우엔 단순히 코딩만 따라치는게 전부였습니다. 저는 조금 쉽
koreadatascientist.tistory.com
우리가 원하는 것은 아래의 두가지입니다.
- A컬럼의 값에 내가 정해놓은 함수 return 값을 일괄적으로 적용하기 (컬럼 일괄 변경)
- df라는 데이터프레임 전체에 내가 정해놓은 함수 return 값을 일괄적으로 적용하기 (데이터프레임 일괄 변경)
위의 두가지는 파이썬의 기본적인 함수 정의 구문(def)을 통해서 함수를 정의 한 뒤에,
pandas의 apply를 활용하여 일괄 적용 할 수 있습니다.
뿐만 아니라, 간단한 함수는 lambda라는 방식을 활용하여 더욱 간편하게 쓸 수 있습니다.
우선 첫번째(컬럼 일괄변경)를 시행해봅시다.
우리는 특정 컬럼에 대해서 내가 정의한 함수를 적용하고 싶습니다.
그렇다면 우선 함수를 정의해야 겠지요?
모든 값에 1을 더하는 코드를 작성해봅시다
그래서 아래와 같은 함수(plus_one)을 정의하였습니다.
def plus_one(x):
x += 1
return x
해당 함수를 우리가 기존에 정의한 데이터프레임 중 A컬럼에 대해 적용하려면 아래와 같이 pandas의 apply 함수를 적용합니다.
코딩 표기방법은 "데이터프레임["컬럼"].apply(함수명)" 입니다.
df['A'].apply(plus_one)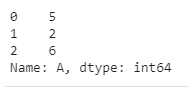
물론 해당 결과는 시리즈로 나올 겁니다.
왜냐면 특정 컬럼만을 적용하였으니 데이터프레임이 아닌 시리즈로 나오는게 정상이기 때문입니다.
(시리즈와 컬럼은 둘 다 같은 개념이라고 보면 편합니다.)
그러므로 기존의 데이터프레임은 아직 바뀐게 아닙니다.
이것을 기존에 데이터프레임에 적용하고 싶으면 다시 객체를 해당 컬럼에 할당시키면 됩니다.
df['A'] = df['A'].apply(plus_one)이제 기존의 데이터프레임과 바뀐 데이터프레임의 두 결과를 비교해봅시다
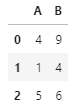
기존

바뀐 데이터프레임
A컬럼의 값이 1씩 증가된것을 알 수 있습니다.
자 여기서 조금 이 과정을 간편하게 하는 방법이 없을까요?
바로 apply(함수) 대신 apply(lambda)를 활용하는 방법입니다.
lambda에 대한 설명
lambda는 def와 같은 함수와 동일한 기능을 합니다.
다만 한 줄 내에 간편하게 사용할 수 있습니다.
기존에 def 함수이름(변수): return 결과값 처럼 길고 복잡하게 할 필요가 없습니다.
물론 복잡한 함수라면 lambda보다는 기존 함수를 권합니다.
단순한 사칙연산이라든가, 간단한 문자열 추출이라든지 이러한 것들에는 lambda를 적용한 apply 함수가 더욱 좋습니다.
표현방법은 "lambda 입력변수 : 리턴값" 으로 나타내면 됩니다.
방금 만들었던 plus_one 함수와 동일하게 lambda로 표현해보겠습니다.
데이터프레임을 초기화합니다.
df = pd.DataFrame([[4, 9], [1, 4], [5, 6]], columns=['A', 'B'])
파이썬 기본 함수기능과 동일한 lambda를 적용하려면 아래와 같이 입력합니다.
def로 만드는 것 대신 lambda로 만들려면 'lambda 입력값 : 결과값' 순으로 입력합니다.
이 자체가 어떤 기능을 할 순 없고 apply(lambda 입력값 : 결과값)으로 적용시켜줘야 합니다.
# lambda를 활용한 apply
df['A'].apply(lambda x : x+1)
# 기존 데이터프레임 변경
df['A'] = df['A'].apply(lambda x : x+1)
자 이제 데이터프레임 전체 값을 일괄적으로 바꾸는 두번째 방법을 생각해봅시다.
재밌는건, 컬럼의 값들을 바꿔주는 방법과 크게 다르지 않다는 겁니다.
위에서는 "데이터프레임['컬럼'].apply(함수)" 를 했다면, 이제는 단순히 "데이터프레임.apply(함수)" 를 하면 됩니다.
새로운 데이터프레임을 생성해봅시다.
df = pd.DataFrame([[2, 4, 9], [3, 1, 4], [9, 5, 6]], columns=['A', 'B', 'C'])
위에서 배웠던 방식대로 기존 def를 적용하는 방식과 lambda를 활용하는 방식을 모두 나타내보겠습니다.
# 정의한 함수를 apply에 적용하는 방식
df.apply(plus_one)
# lambda를 정의하여 apply에 적용하는 방식
df.apply(lambda x : x+1)
두 결과 모두 동일하게 나타났습니다.
주의해야 될 점은, 아직까지 기존에 있는 데이터프레임 자체가 변하지는 않았다는 겁니다.
기존 데이터프레임에 적용하고자 한다면, df에 다시 할당해줘야함을 잊어서는 안됩니다 !
apply를 적용한 다른 예시
여기에 추가로, A컬럼과 C컬럼에만 plus_one 함수를 적용하고 싶다면 어떻게 해야될까요?
그렇다면 두가지 방법을 생각해볼 수 있겠네요.
- A컬럼을 apply해서 할당하고, C컬럼을 apply해서 할당한다. 즉 Series(column)마다 할당하는 방식
- A컬럼과 C컬럼을 동시에 데이터프레임으로 만든 상태에서 전체를 할당한다. 즉 DataFrame을 적용하는 방식
어느방법이든 좋지만 저같은 경우에는 2번 방법이 조금 더 편할 것 같습니다.
df[['A', 'C']] = df[['A', 'C']].apply(plus_one)
기존 데이터프레임에서 A와 C컬럼에 대해서만 함수가 적용되었네요.
해당 방식은 lambda 함수를 적용해도 동일한 결과가 나옵니다.
다른 모듈의 함수와 apply를 적용하는 방법
재밌는거 하나 더 알려드리자면,
numpy 함수나 다른 라이브러리의 연산함수들도 모두 apply를 적용할 수 있다는 겁니다.
df = pd.DataFrame([[2, 4, 9], [3, 1, 4], [9, 5, 6]], columns=['A', 'B', 'C'])
df.apply(np.sqrt) # 모두 제곱근으로 바꾸기np.sqrt는 numpy라는 라이브러리에서 제곱근으로 바꿔주는 함수입니다.
보통 np.sqrt(값) 형태로 씁니다.
그런데 이것을 apply와 적용시키면 해당 데이터프레임 혹은 컬럼이 제곱근을 생성합니다.

이처럼 apply 함수는 내가 정의한 함수 외에도 기존 다른 라이브러리의 함수들도 적용시킬 수 있습니다.
apply 함수는 사용자의 방식에 따라 다양한 결과를 이끌어낼 수 있습니다.
하지만 큰 뼈대는 제가 오늘 알려드린 것들이라는 것을 잊지 마시기 바랍니다.
마지막으로 우리가 한 내용을 줄기로 분류해서 다시 정리해보겠습니다.
[핵심요약]
- 함수를 적용하는 방법
- apply를 적용
- def로 정의한 함수를 적용
- lambda로 정의한 함수를 적용
- apply를 적용
- 시리즈, 데이터프레임 모두 동일하게 적용 가능하다
- 다만, 해당 결과가 실제로 그 데이터프레임과 시리즈를 바꾼것이 아니므로 다시 할당시켜줘야 한다.
- 다른 라이브러리의 함수를 적용시킬수도 있다.
- ex. numpy의 sqrt 함수
출처:
'파이썬' 카테고리의 다른 글
| [pandas]결측값 채우기, 결측값 대체하기, 결측값 처리 (filling missing value, imputation of missing values) : df.fillna() (0) | 2022.08.20 |
|---|---|
| [Python] pandas 문자열 관련 함수 str (0) | 2022.08.18 |
| [Pandas]Pandas의 DataFrame에서 두 개의 텍스트 열 결합 (0) | 2022.08.18 |
| [Pandas 기초] 데이터프레임 합치기(merge, join, concat) (0) | 2022.08.18 |
| [Pandas 기초]5.Pandas 데이터 파일 입출력 (0) | 2022.08.17 |
댓글